
Como ya se ha visto en entradas anteriores, Asterisk verifica la identidad del usuario antes de aceptar peticiones de tipo REGISTER o INVITE, comprobando que el password de la extensión desde la que se envían esas peticiones es el correcto. En el caso de una petición tipo REGISTER, el esquema es el siguiente:

Esquema de una petición tipo REGISTER
Se observa que, inicialmente Asterisk responde siempre con un mensaje de tipo 401 Unauthorized a la petición de Register por parte de la extensión, la cual envía una segunda petición de Register que, esta vez si es aceptada por Asterisk. En la siguiente captura de pantalla se muestra de forma práctica la señalización entre una extensión SIP con número 101 y situada en la dirección IP 10.22.86.43, y un servidor de Asterisk situado en la dirección IP 10.22.86.250

Register de una extensión SIP en Asterisk
Si examinamos la petición inicial realizada por la extensión SIP, observamos que en ninguno de sus campos aparece el password de la extensión, por lo que Asterisk no puede saber si se trata de una extensión legítima o no.
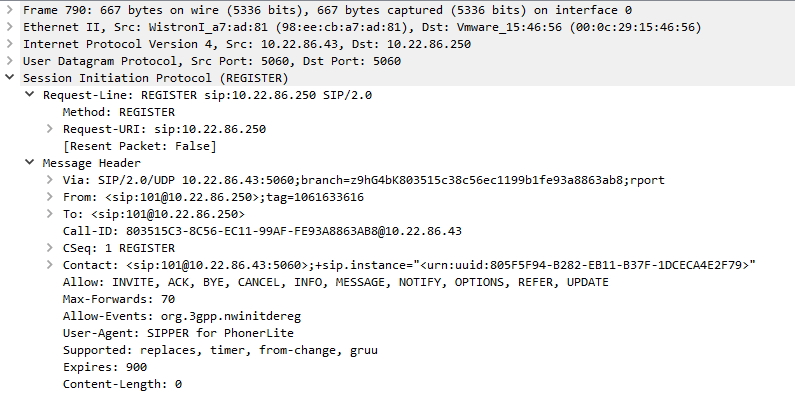
Petición inicial de tipo Register
Antes de proceder con el registro de la extensión, Asterisk necesita comprobar que dicha extensión es una extensión legítima del sistema, es decir, que su password coincide con el password almacenado en el fichero sip.conf. Al igual que la mayoría de los sistemas informáticos actuales, Asterisk no requiere que se le envíe de forma directa dicho password, ya que podría ser interceptado por un posible espía. En su lugar, Asterisk le envía a la extensión SIP una respuesta de tipo 401 Unauthorized, en cuyo contenido le indica que utilice el algoritmo MD5 con un número de un solo uso o “nonce” que también se adjunta en dicha respuesta.
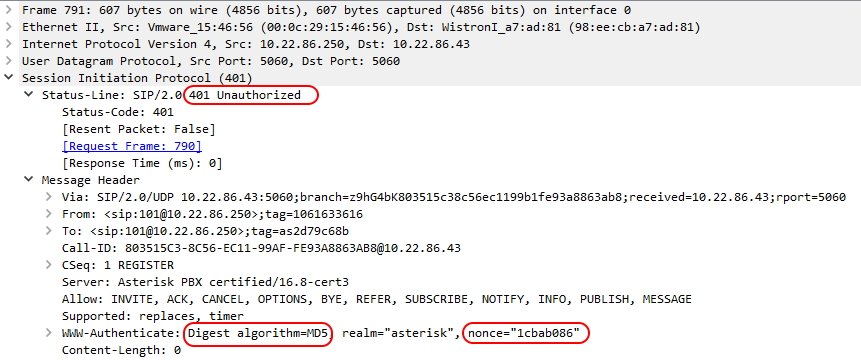
Respuesta 401 con indicación de uso de MD5 y número “nonce”
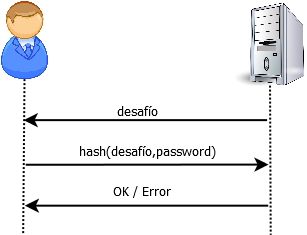
El uso del algoritmo de hash MD5 y el número aleatorio “nonce” forma parte de un protocolo de tipo “desafío-respuesta” en el que Asterisk le somete a la extensión SIP al desafío de calcular un valor numérico mediante el algoritmo MD5 y comprueba posteriormente la respuesta. Si la respuesta enviada por la extensión SIP coincide con la respuesta obtenida por Asterisk al hacer el mismo cálculo, Asterisk acepta la petición de Register. Si la respuesta enviada por la extensión fuera diferente a la calculada por Asterisk, se rechaza la petición de Register. Estos sistemas de autenticación basados en un proceso de “desafío-respuesta” son considerablemente más seguros que los sistemas básicos en los que la contraseña o password es enviada directamente y, por tanto, puede ser capturada fácilmente por un atacante.

Autenticación básica, con envío directo del password (Incibe-Cert)
Autenticación mediante un protocolo de tipo “desafío-respuesta” (Incibe-Cert)
El desafío propuesto por Asterisk a la extensión SIP para admitir su petición de tipo Register consiste en que ésta calcule un valor de Hash mediante el algoritmo MD5. Como entradas de ese algoritmo de Hash está el password almacenado en la extensión, el número aleatorio “nonce” enviado por Asterisk y otros valores que se indicarán a continuación. La respuesta del algoritmo MD5 es una cadena de 128 bits, única para cada par contraseña-nonce y que, aunque fuera interceptada por un atacante, no permite el cálculo de la contraseña.

Nueva petición de Register enviada por la extensión SIP con el campo “response”
![]()
Detalle de la respuesta calculada mediante el algoritmo MD5
El algoritmo MD5 fue desarrollado en 1991 por Ronald Rivest, profesor del MIT, y toma ese nombre porque sustituye al algoritmo MD4, desarrollado anteriormente por el mismo profesor y que en esos momentos no se consideraba totalmente seguro. MD5, al igual que el resto de algoritmos de hash debe cumplir con las dos siguientes propiedades:
- Es un algoritmo “de un solo camino”, es decir, a partir de la entrada al algoritmo es fácil calcular el hash de salida, pero a partir de este hash no es posible calcular la entrada.
- Debe estar libre de “colisiones”, es decir, no puede haber dos entradas distintas que den lugar al mismo hash de salida.
La primera de las condiciones se cumple en MD5 y en otros algoritmos de tipo “resumen” pero la segunda condición no es posible cumplirla con un hash de tamaño limitado. En el caso de MD5, al producir en su salida un hash de 128 bits, se verifica que si el número de entradas al algoritmo es mayor que 2128, necesariamente se producirá una colisión.
El algoritmo MD5 acepta como entrada cualquier cadena alfanumérica de longitud indefinida, pudiendo servir para obtener el hash de una contraseña de pequeña longitud o el hash de un mensaje de texto de gran longitud. MD5 comienza dividiendo el mensaje de entrada en bloques de 512 bits, y si la longitud del mensaje no es múltiplo exacto de 512, entonces añade una cadena formada por un “1” y tantos “0” como sean necesarios hasta una longitud de 448 bits, añadiendo posteriormente un bloque de 64 bits que contiene el valor numérico de la longitud del mensaje.
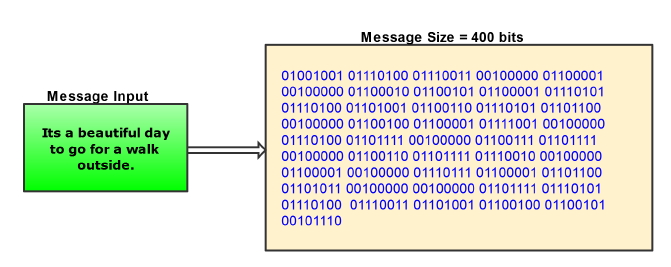
Primer paso del algoritmo MD5: digitalización del mensaje de entrada
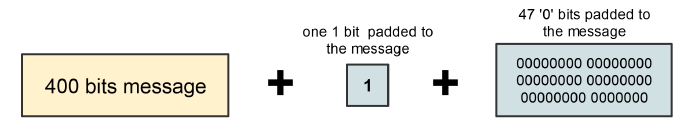
El mensaje se “completa” hasta una longitud de 448 bits
MD5 procesa cada uno de estos bloques de 512 bits de forma encadenada, de tal manera que la salida de cada bloque es una cadena de 128 bits dividida en 4 variables de 32 bits denominadas A, B, C y D. Estas variables de 32 bits influyen en el proceso de cálculo del siguiente bloque. La salida del último bloque es el valor de hash buscado de 128 bits.
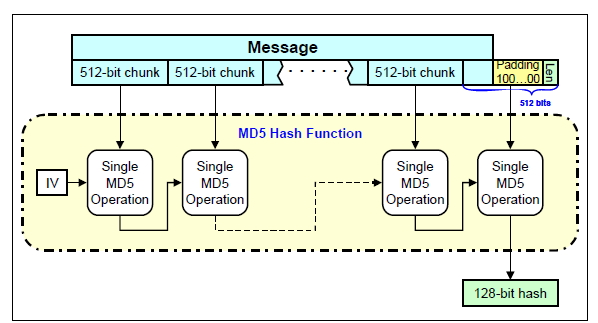
Proceso “en cadena” de los bloques de 512 bits
La entrada al primer bloque de 512 bits es un conjunto de 4 variables de 32 bits cada una, denominadas A, B, C y D. Estas variables toman los siguientes valores:
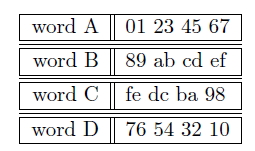
Valores iniciales de las variables A, B, C y D
A cada uno de los bloques de 32 bits del mensaje original se le aplica un proceso de 4 rondas, en las que intervienen las variables A, B, C y D y también unas constantes obtenidas de una tabla diseñada especialmente para evitar la aparición de “patrones regulares” en los resultados y, por tanto, conseguir que éste sea lo más aleatorio posible. En cada una de las cuatro rondas se aplican los siguientes pasos:
- Se calcula la función F a partir de las variables B, C y D mediante las operaciones lógicas and, or, not y xor. Esta función F es diferente para cada una de las cuatro rondas.
- El resultado F se suma a la variable A en módulo 232, es decir, el resultado es el resto de dividir la suma entre 232, es decir, será también un valor de 32 bits.
- El resultado anterior se suma también en módulo 232 con el correspondiente bloque Xi de 32 bits del mensaje original que se está procesando en ese momento.
- El resultado anterior se suma, de nuevo en módulo 232 con un valor Ki obtenido de la tabla “random” señalada anteriormente. Este valor Ki es diferente para cada una de las 4 rondas que se aplica a cada uno de los 16 valores Xi del mensaje de entrada, es decir, la tabla “random” contiene 64 valores Ki distintos (calculados realmente mediante una función seno).
- El resultado anterior se desplaza n bits a la izquierda según los valores de una tabla precalculada.
- El resultado anterior se suma en módulo 232 con la variable B y pasa a ser la nueva variable B para la siguiente ronda. A su vez la variable B pasa a ser la variable C de la siguiente ronda, C pasa a ser la variable D y D pasa a ser la variable A.
- Con estos nuevos valores calculados de A, B, C y D se pasa a tratar otro nuevo bloque Xi de 32 bits del mensaje original de 512 bits. El último bloque Xi del mensaje producirá la salida A, B, C y D para tratar el siguiente bloque de 512 bits, y si ya es el último, esas variables concatenadas formarán el hash de salida de 512 bits del algoritmo MD5.
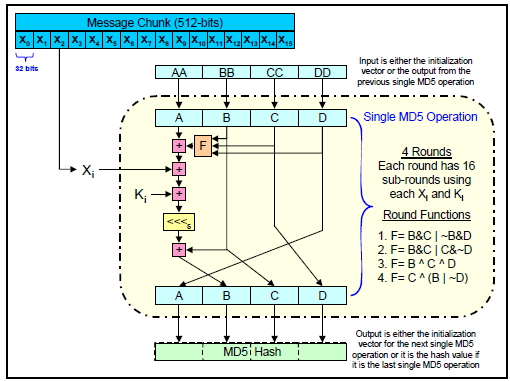
Diagrama de las operaciones realizadas con cada bloque de 512 bits
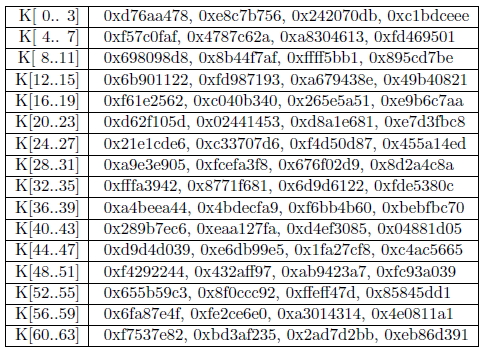
Tabla con los valores “random” Ki para sumar en cada uno de los 64 pasos

Tabla con los valores Si para hacer el desplazamiento de n bits a la izquierda
Una vez visto, de forma resumida, el funcionamiento del algoritmo MD5, queda por ver como se forma el mensaje original que procesa dicho algoritmo, tanto en la extensión SIP como en el propio Asterisk. Este mensaje original contiene, lógicamente, el password de la extensión y el número aleatorio “nonce”, pero también contiene otros valores, a fin de dificultar aun más un posible ataque al algoritmo MD5.

Composición del mensaje para el algoritmo MD5
Es decir, para calcular la respuesta, en realidad se aplica tres veces el algoritmo MD5, una vez para calcular el valor HA1, otra vez para calcular el valor HA2 y una última vez para calcular la respuesta a partir de los valores anteriores HA1, HA2 y el número “nonce”. Los valores username, realm, method y digestURI aparecen en la petición de REGISTER, y en la captura con Wireshark mostrada inicialmente, estos valores son:
- username: 101
- realm: asterisk
- password: 101101
- method: REGISTER
- digestURI: sip:10.22.86.250
- nonce: 1cbab086
Aplicando estos valores en una calculadora MD5 de las muchas que hay disponibles en la red, calculamos en primer lugar HA1 = MD5(username:realm:password)

HA1
En segundo lugar calculamos HA2 = MD5 (method:digestURI)
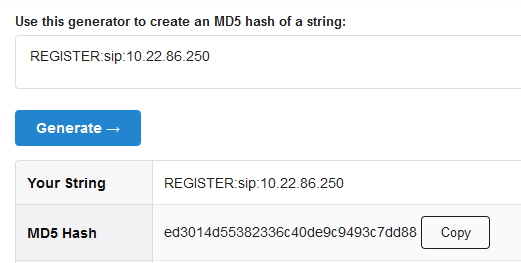
HA2
Y por último calculamos la respuesta, que es: response = MD5 (HA1:nonce:HA2)
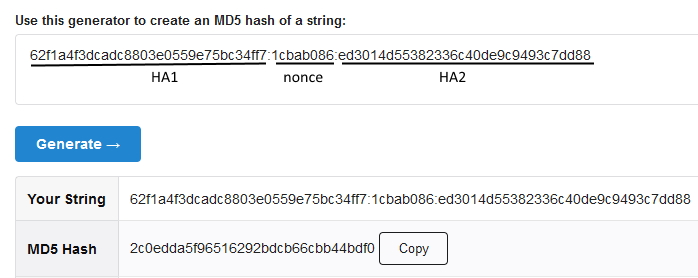
Response
Donde se observa que coincide con el valor enviado por la extensión SIP al servidor de Asterisk
![]()
Valor “response” enviado por la extensión SIP al servidor de Asterisk
Es de señalar que la autenticación mediante el algoritmo MD5 también es solicitada por Asterisk a cualquier extensión que envía un mensaje INVITE para realizar una llamada a través del dialplan.
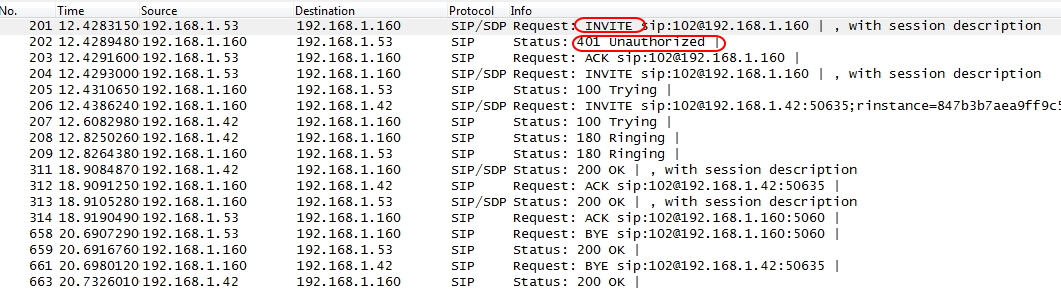
Ejemplo de respuesta “401 Unauthorized” al INVITE de inicio de llamada
En cuanto a la fortaleza del algoritmo MD5 se puede afirmar que su uso ya no es recomendable para aplicaciones de tipo general, como por ejemplo aquellas en las que se almacenan una gran cantidad de hash de contraseñas en una base de datos. En estos casos, si el atacante logra acceder a la base de datos, es factible un ataque por alguno de los siguientes métodos:
- ataque de fuerza bruta: se van probando todas las contraseñas posibles hasta encontrar una cuyo hash coincide con uno de los hash almacenados en la base de datos. Es un procedimiento que exige una potencia de cálculo considerable y, en función de la longitud y composición del password, unos tiempos de proceso a veces inviables (horas, días e incluso años, dependiendo de la potencia de cálculo empleada).
- ataques de diccionario: es una variante del ataque de “fuerza bruta” en el que solo se prueban aquellas contraseñas más utilizadas. Con esto se acorta el tiempo de ataque pero puede ser que no se obtenga ninguna contraseña válida, por no estar incluida en el diccionario utilizado para el ataque.
- ataques de diccionario avanzado: utilizan un diccionario con las contraseñas más comunes pero van sustituyendo caracteres típicos que los usuarios acostumbran a cambiar para dar mas fortaleza a las contraseñas, por ejemplo, sustituir la letra “a” por “@”, la letra “o” por el número “0” y otros cambios similares.
- ataques basados en tablas de hash (Lookup Tables): se cuenta con tablas que contienen una gran cantidad de hash correspondientes a las contraseñas más habituales. Respecto de los métodos de diccionario, esto acelera el proceso de búsqueda de contraseñas válidas, ya que no es necesario realizar los cálculos de hash de las posibles contraseñas sino tan solo comparar la tabla de hash con los valores de hash almacenados en la base de datos atacada. Al igual que los métodos de diccionario, tampoco asegura un éxito en la operación y, por el contrario, requiere de un espacio de almacenamiento muy elevado si la contraseña tiene un cierto número de caracteres (por ejemplo, para almacenar todas las posibles contraseñas de 8 caracteres de un alfabeto de 26 caracteres, se necesitan 26x26x26x26x26x26x26x26 = 268 octetos de memoria, que son aproximadamente 1,5 TB, y eso sin tener en cuenta los correspondientes hash).
Todos estos ataques son de tipo “off line”, requieren el acceso a la base de datos donde se almacenan los hash y encuentran una dificultad cuando en el cálculo del hash interviene, además del password del usuario, un valor aleatorio, como es el valor nonce que genera el servidor de Asterisk, por lo que el uso de MD5 se considera lo suficientemente seguro para la autenticación en el protocolo SIP.
Por otro lado, también se pueden producir ataques de tipo on line, que son aquellos en los que el ataque se produce probando password aleatorios o de diccionario contra un sistema en funcionamiento, pero este tipo de ataques son poco efectivos en el caso de Asterisk, ya que aplicaciones como Fail2ban son capaces de detectarlos fácilmente y bloquear las direcciones IP desde las que se producen dichos ataques.

Ron Rivest, Adi Shamir y Leonard Adleman
En la fotografía, Ron Rivest, Adi Shamir y Leonard Adleman, creadores en 1977 del muy conocido algoritmo RSA, empleado para el cifrado de las comunicaciones mediante un sistema de clave asimétrica (clave pública – clave privada), basado en la factorización de números primos.
El texto excelente, pero yo no me quedo corto en la divulgación tecnológica: tprotegiendo tus datos con md5